Today I’m sharing some results of my experiments with coding LLMs from scratch in python/ PyTorch without any extra libraries.
The purpose of this is obviously educational. For me the true value of this is in struggling, running into issues/ bugs and correcting them by myself; however I’m sharing the code because sometimes it can be helpful to solve some frustrating issue by looking at other implementations.
Probably, like many other I got inspired by fantastic tutorial by Andrej Karpathy on GPT-2 from scratch. The material he prepared is a true treasure trove but it’s biggest value for me was the idea/realisation that I can code and train the modern LLM architectures (albeit smaller size) without any major problems or costs fully on my own!
Working as data scientist for many past years, I used multiple Transformer based models, including most of the LLMs out there; for some I modified or extended the code, then also I did the basic transformer implementation multiple times on my own to learn how it works but I never really did the entire language model from start to end with all the training on my own … until now.
I first started following Karapathy tutorial but then inspired by it, I just moved on to all famous LLMs shared by other major companies. As up to the date of publication of this post I implemented:
- GPT-2 – as an example of decoder based LLM
- BERT – opposed to GPT-2, example of encoder based Language Model
- Llama2 – similar to GPT-2 but having some interesting modifications (like rotary positional embeddings which are used by pretty much everybody nowadays).
- T5 – example of encoder-decoder based model like the one from original Attention Is All You Need paper
I think the most I got out of my BERT implementation – that is because there aren’t many open / tutorial like implementations out there. I found few but usually they don’t do the full pre-training so it’s hard to compare my own results. Therefore, many problems and issues I had to solve myself, basically following similar methodology as Karapathy for his GPT-2 tutorial – reading the BERT and subsequent RoBERTA papers to figure out all the tiny implementation details. I also peaked into HuggingFace implementation but as noted also in GPT-2 tutorial, its super convoluted. I when ran into multiple frustrating issues, I basically ripped the entire code apart line-by-line. Time consuming but ended being quite satisfactory (after all started finally working ;D).
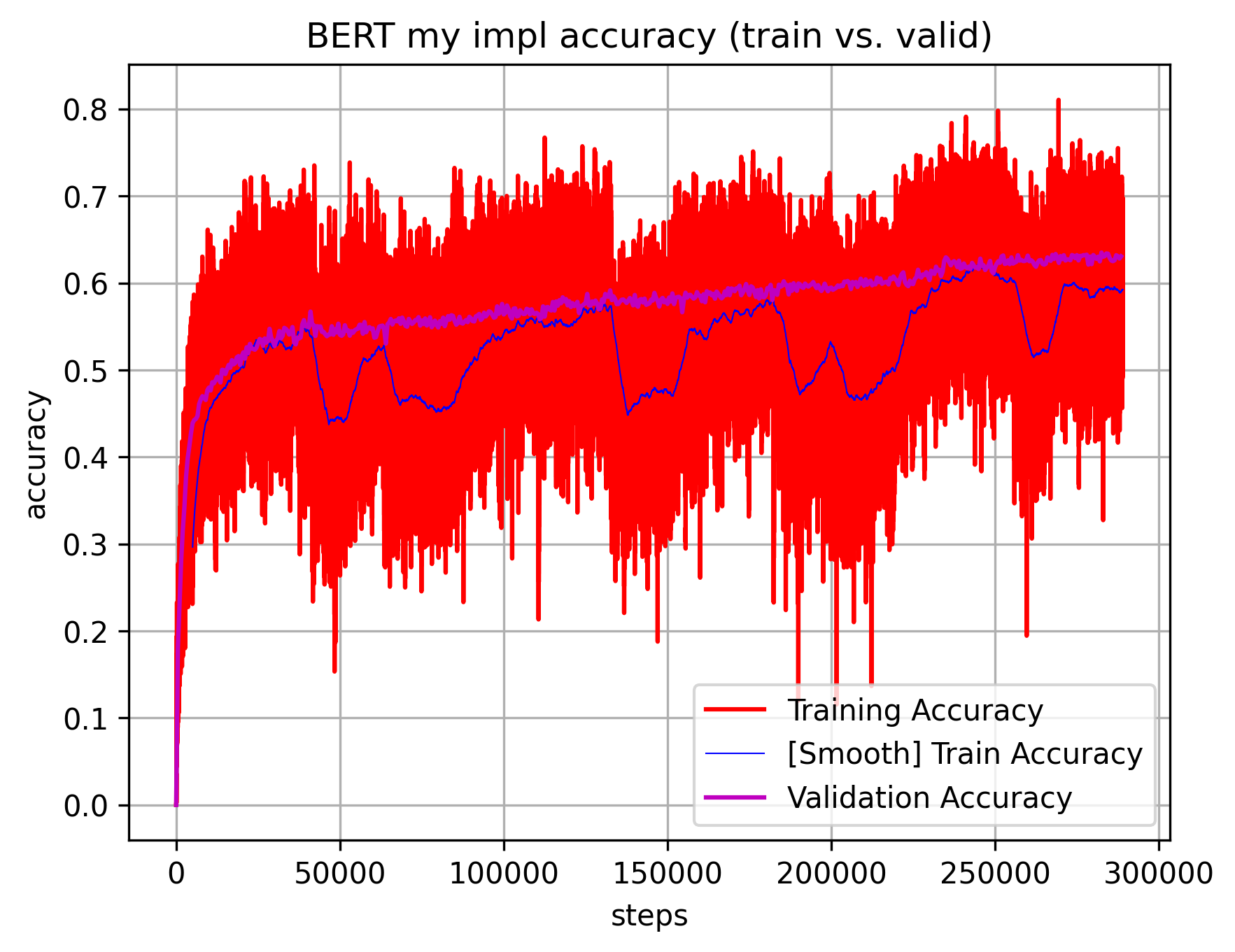
Overall, I can recommend the entire exercise even for those who have nothing to do with pre/post training those huge LLMs. I don’t expect myself to do that either during my every day regular work any soon, however I fine-tune on smaller datasets all those major models with billions of parameters pretty much on a daily basis. Understanding with great detail how they are implemented and what are the differences between them makes me feel a lot more comfortable working with all this. Also, doing it all from scratch in PyTorch is quite a good exercise.
For anybody interested, I share all my code and all pre-training results/accuracies/settings in a new repository on my Github account.